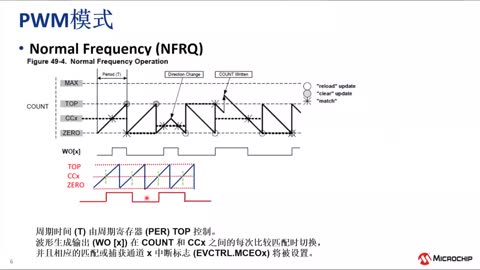
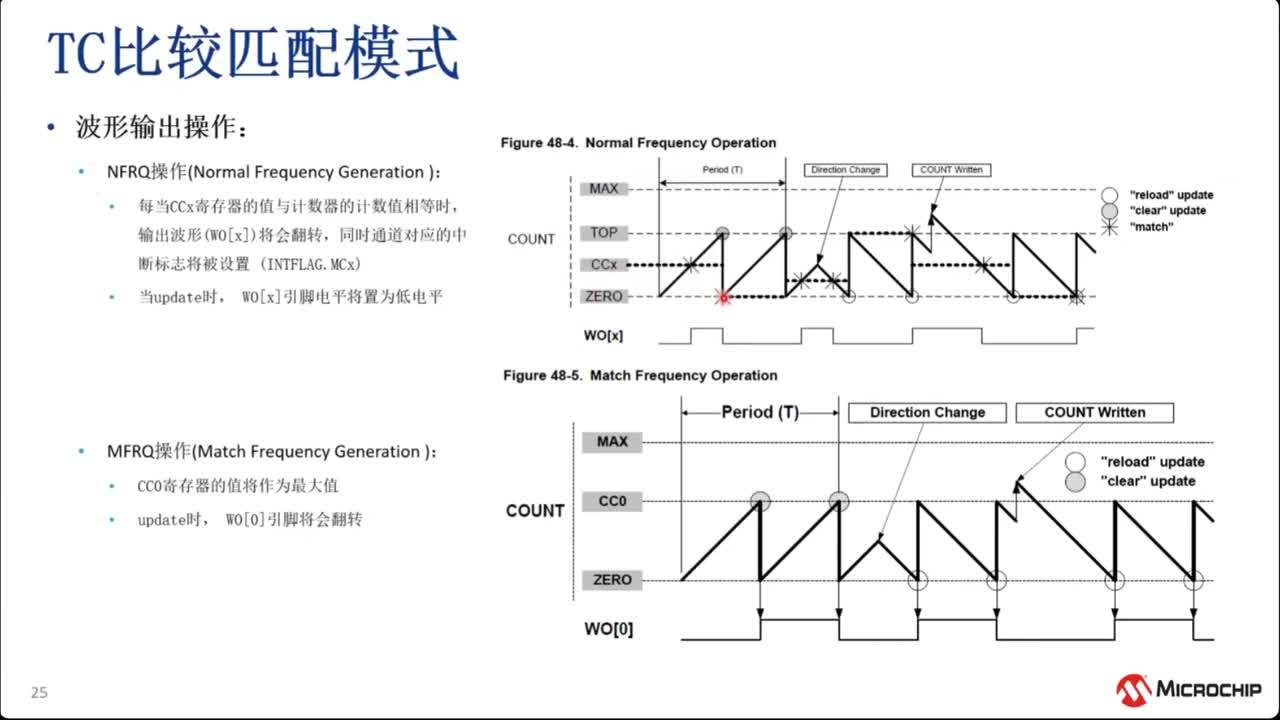
|
1 �� �� ���ڴ�����늈�ͨ�š����غ͔�(sh��)��(j��)�ɼ����I�������V���đ��ã��^�����(sh��)Ƕ��ʽ̎��������(n��i)����ͨ�î����հl(f��)��(UART)��UART��(sh��)��(j��)��ݔ��Ҫͨ�^�Д��DMA�ķ�ʽ���F(xi��n)�� �Дʽ���ڽ��յ���(sh��)��(j��)����Ҫ�l(f��)�͔�(sh��)��(j��)�r�a(ch��n)���Д࣬���Д���ճ������x��UART�ľ��_�^(q��)(FIFO)���F(xi��n)��(sh��)��(j��)��ݔ�����ڴ���ͨ������һ����^��(����ֵ�����^115 200 bps)�������(sh��)Ƕ��ʽϵ�y(t��ng)�������Дʽ���ݔ���ڔ�(sh��)��(j��)��Ȼ�����Д���ճ�����Ҫռ��CPU�ĕr�g���������ٶȵ�����Ҳ�،�����CPU���l����푑�UART�Д࣬�@�ݱؕ����Ƕ��ʽϵ�y(t��ng)�������½��� DMA��(sh��)��(j��)��ݔ�o��CPU�ą��c����һ�N���Ӹ�Ч�Ĕ�(sh��)��(j��)��ݔ��ʽ���F(xi��n)�е�DMA��(sh��)��(j��)��ݔ�������ǻ���DMA�K��ݔ��ʽ(��Block DMA)���@�N��ʽ��ÿ��ݔ��һ����(sh��)��(j��)�K��a(ch��n)��һ��DMA�Д࣬�ڸ��ٴ���ͨ���У��l����DMA�Д���Ȼ��Ӱ�ϵ�y(t��ng)�����ܡ����Ļ���ɢ��DMA(seatter DMA)�Ă�ݔ��ʽ�����һ�������Ĺ��I(y��)�����ٴ����(q��)���OӋ���������F(xi��n)�˲����ʸ��_12 Mbps��UART��(sh��)��(j��)��ݔ�� 2 DMA��(sh��)��(j��)��ݔ?sh��)����c DMA(Direct Memory Access��ֱ�Ӵ惦���L��)����ָ��(sh��)��(j��)�ڃ�(n��i)���cI��O�O���g��ֱ�ӂ�ݔ����(sh��)��(j��)������DMA������(DMAC)��ɶ�����ҪCPU�ą��c����������CPU�������ʡ���ˣ�DMA�Ǹ��ٔ�(sh��)��(j��)��ݔ?sh��)����뷽ʽ������DMA�M�Д�(sh��)��(j��)��ݔ�r��ע�������c�� ��DMA��ݔ��Ҫռ��ϵ�y(t��ng)�������ڴ����gCPU����ʹ�ÿ�����������O���M�Д�(sh��)��(j��)��ݔ�r�������κε��g�࣬�ͱ�횱��C��ݔ���gDMAC��ϵ�y(t��ng)�����Ī�ռ���@���ܕ�Ӱ�������Ҫʹ�ÿ����M�Д�(sh��)��(j��)��ݔ?sh��)��O�䡣���ԣ�ϵ�y(t��ng)������DMA��ݔ���g�Ƿ�ɱ���ռ��Ҫ����(j��)Ƕ��ʽϵ�y(t��ng)���ض��h(hu��n)����Q���� ��DMA��ݔ���ھ���һ����(cache coherency)���}����D1��ʾ��DMAC��CPU�ǃɂ�ƽ�еĆ�Ԫ��CPU����ͨ�^��(sh��)��(j��)������L����(n��i)���еĔ�(sh��)��(j��)����DMAC�tֱ���L����(n��i)�档�����(n��i)���еĔ�(sh��)��(j��)��DMAC���£�����(sh��)��(j��)�����еĔ�(sh��)��(j��)��δ�����£�CPU�@�õ�ijЩ��ַ��ֵ���ܲ����ǃ�(n��i)���е��挍ֵ�����˱����@�����}������DMAC�������(n��i)�攵(sh��)��(j��)���CPU�xȡ�������^�Ĕ�(sh��)��(j��)ǰˢ��(sh��)��(j��)���棬����ʹ�ò�����(sh��)��(j��)����ӳ��ķǾ���(non-cacheable)��(n��i)��^(q��)�� DMA��(sh��)��(j��)��ݔ�ɷ֞�K��ݔ��ɢ�Ђ�ݔ�ɷN��ʽ����DMA��ݔ��(sh��)��(j��)���^���У�Ҫ��Դ������ַ��Ŀ��������ַ������B�m(x��)�ġ�������ijЩӋ��C�wϵ��(��IA�ܘ�)���B�m(x��)�Ĵ惦����ַ�������ϲ�һ�����B�m(x��)�ģ�����DMA��ݔҪ�ֳɶ����ɡ���ݔ��һ�K�������B�m(x��)�Ĕ�(sh��)��(j��)�����l(f��)һ���Д࣬Ȼ���M����һ�K�������B�m(x��)�Ĕ�(sh��)��(j��)��ݔ���@����DMA�K��ݔ��ʽ(Block DMA)��ɢ�Ђ�ݔ���ډK��ݔ��ʽ�ϰl(f��)չ�����ģ����cһ����ݔ朱����P����D2��ʾ��ԓ朱������dž���Y����h(hu��n)�νY�����������а�����(sh��)��(j��)λ������(sh��)��(j��)�K��С����ǰ�K��ݔ�Y���Ƿ����l(f��)�Д�ȿ�����Ϣ��DMA�K��ݔ�ɿ�����ֻ����һ����(ji��)�c������һ��(ji��)�cָᘿ���ָ��ǰ��(ji��)�c��ɢ�Ђ�ݔ������ɢ��DMA��ʽ�ܸ��`���Ч��ݔ��(sh��)��(j��)�� 3 ��SPEAR300ƽ�_�ό��F(xi��n)���ٴ��� 3.1 Ӳ��ƽ�_ SPEAR300��ST��˾��ARM926EJ-S�˵Ļ��A���_�l(f��)�ĸ�����Ƕ��ʽ̎����������߹����l�ʞ�333MHz����8��������DMAͨ����֧��ɢ��DMA��UART֧��DMA��ݔ���l(f��)�ͺͽ���FIFO��С����16�ֹ�(ji��)����192 MHz�����O����(APB)�l����֧�ֵ���߲����ʞ�12 Mbps��������APB���l��߀���ԫ@�ø��ߵIJ����ʡ����ĵ�Ӳ��ƽ�_����SPEAR300����ĵ��˙C����a(ch��n)Ʒ����Ҫ���O�����|������Һ���@ʾģ�M���W(w��ng)�ںʹ���(����Ҫ֧����߲����ʞ�12 Mbps�����T��MPIͨ�Ņf(xi��)�h)�� 3.2 �(q��)�ӳ����OӋ �����(q��)�ӳ���ĺ����nj��F(xi��n)��(sh��)��(j��)��Ч��(w��n)�����հl(f��)�����ˌ��F(xi��n)UART�ĸ��ٔ�(sh��)��(j��)��ݔ��UART�Д��O�Þ���߃�(y��u)�ȼ���ͬ�r�ڲ���ϵ�y(t��ng)�����S�Д�Ƕ�ף����_UART���ճ��r�Д�RTI��ʹ��UART��DMA��ݔ���@�ӣ���UART�İl(f��)��FIFO��(sh��)��(j��)�p�ٵ��O���ą���ֵ(FIFOLevel)�r���l(f��)��DMA��ݔ�͕����|�l(f��)��ͬ�ӣ�������FIFO�Ĕ�(sh��)��(j��)���L���O��ֵ�r������DMA��ݔ�͕����|�l(f��)�����˜p��DMA��ݔ���|�l(f��)�ĴΔ�(sh��)ͬ�r���C��(sh��)��(j��)�����r��ݔ���l(f��)��FIFO Level�O����2�ֹ�(ji��)��������FIFOLevel�O����14�ֹ�(ji��)�����l(f��)�ͺͽ��յ�FIFO Level�քe�O����0��16�ֹ�(ji��)���кܴ��L�U�ġ�MPI�f(xi��)�hҪ���ݔ?sh��)�һ���?sh��)��(j��)�������g�࣬������ʹ��DMA��ݔUART��(sh��)��(j��)�rDMAC��횪�ռϵ�y(t��ng)���������˱���a(ch��n)������һ���Ԇ��}��ʹ��2�K�Ǿ����(n��i)��^(q��)���Ŵ��l(f��)�͵Ĕ�(sh��)��(j��)���ѽ��յ��Ĕ�(sh��)��(j��)�� �l(f��)�͔�(sh��)��(j��)�r�����l(f��)�͵Ĕ�(sh��)��(j��)��������֪�ġ��Ș���һ����ݔ��(ji��)�c����(sh��)��(j��)Դ��ַ�锵(sh��)��(j��)������ַ��Ŀ�ĵ�ַ��UART�Ĵ�������(sh��)��(j��)λ����8����һ��(ji��)�cָ�(PTR_NEXT)��ա���ǰ��(sh��)��(j��)���l(f��)�ͽY��ǰ�����PTR_NEXT�����£��t��һ����(sh��)��(j��)���Ă�ݔ�Ԅ��_ʼ����ǰ��(sh��)��(j��)���Ƿ�l(f��)���ꮅ����ͨ�^�xȡDMAC�Ĵ���DMACCnControl��TransferSize�ֶε�֪�������l(f��)�͔�(sh��)��(j��)���^�̟o���|�l(f��)�κ��Д࣬���̈D��D3��ʾ���������DMA�K��ݔ��ʽ������Ҫ��ÿ��ݔ�ꮅ��a(ch��n)��DMA�Д࣬�����b�d��(sh��)��(j��)����(n��i)���еİl(f��)�͔�(sh��)��(j��)�^(q��)�l(f��)����һ����(sh��)��(j��)���� ���Ք�(sh��)��(j��)�r�������l(f��)�^���Ĕ�(sh��)��(j��)��һ����δ֪�ġ����캬��100����(ji��)�c��ѭ�h(hu��n)朱��Y����ÿ����(ji��)�c�����Ă�ݔ�K��С�����FIFO Level����(sh��)��(j��)Դ��ַ��UART��(sh��)��(j��)�Ĵ����ĵ�ַ����(ji��)�c��Ŀ�ĵ�ַ����Ք�(sh��)��(j��)��(n��i)��^(q��)�����ַ���˺�(ji��)�c��Ŀ�ĵ�ַÿ�����ƫ��(FIFO Level��2)���ֹ�(ji��)����(sh��)��(j��)λ����16(8����(sh��)��(j��)λ��4����B(t��i)λ��4������λ)�������յ��Ĕ�(sh��)��(j��)�_�����Ճ�(n��i)��^(q��)���80��(RECV_TH)�r����Ҫ֪ͨ��(sh��)��(j��)�l(f��)�ͷ�ֹͣ��(sh��)��(j��)��ݔ���ڵ�80����(ji��)�c̎�O��DMA�Д࣬ԓ��(ji��)�c���ֵ��(ji��)�c�����ñ��ĵ��OӋ��������1�������^RECV_TH��С�Ĕ�(sh��)��(j��)�����a(ch��n)��һ��RTI�Дࡣ�����յ��Ĕ�(sh��)��(j��)������FIFOLevel�r�����|�l(f��)DMA���գ���RTI�Д��а�UART����FIFO�еĔ�(sh��)��(j��)���Ƶ���(n��i)���еĔ�(sh��)��(j��)���Յ^(q��)��ͬ�rʹDMA���չ�(ji��)�c��Ŀ�ĵ�ַ���ƫ���������L�Ȳ������ֵ��(ji��)�c��λ�á����Ք�(sh��)��(j��)������D4��ʾ���������DMA�K��ݔ��ʽ���ͱ���~��ʹ��һ���h(hu��n)�Δ�(sh��)��(j��)���_�^(q��)(Ring Buffer)��ÿ�ν��յ�ָ����С�Ĕ�(sh��)��(j��)�K��a(ch��n)��DMA�Д࣬���Д���ճ����Ќ����յ��Ĕ�(sh��)��(j��)���Ƶ��h(hu��n)�Δ�(sh��)��(j��)���_�^(q��)�С� 3.3 �(q��)�Ӝyԇ ���ĵ��OӋ����ֱ�ӑ����ڹ��I(y��)����HMI�a(ch��n)Ʒ����횽�(j��ng)�^����Ĝyԇ������3�_���T��S7ϵ��PLC��1�_�a(ch��n)Ʒ�әC����ƾW(w��ng)��ʹ�����T��MPI�f(xi��)�h�M�Мyԇ�������Ô�(sh��)��(j��)��������ProfiTrace�O(ji��n)�yͨ���^�̡��yԇ�Y��������2 400 bps��12 Mbps�ĸ����������¶����M�з�(w��n)���Ĕ�(sh��)��(j��)ͨ�š� �Y �Z ����Ԕ����B��DMA��(sh��)��(j��)��ݔ?sh��)����c��ɢ��DMA�Ĺ�����ʽ���ڴ˻��A�ϣ������һ����ɢ��DMA�ĸ��ٴ����(q��)���OӋ�������l(f��)�͔�(sh��)��(j��)��ȫ��DMAC��ɣ��o���|�l(f��)�κ��Д࣬����1�������^���Յ^(q��)�ֵ�Ĕ�(sh��)��(j��)���a(ch��n)��1��RTI�Дࡣ�ͬF(xi��n)�еĸ��N����DMA�K��ݔ�M�д��ڔ�(sh��)��(j��)ͨ�ŵķ�����ȣ��Д�Δ�(sh��)����p�٣��������˔�(sh��)��(j��)��ݔ?sh��)�Ч�ʡ��ڑ����˱��������˙C����a(ch��n)Ʒ�ϣ����F(xi��n)�˲����ʸ��_12 Mbps�ķ�(w��n)����(sh��)��(j��)��ݔ������������ƽ�_���OӋ���F(xi��n)���ٴ��ڣ���������һ���ܺõą����� |