|
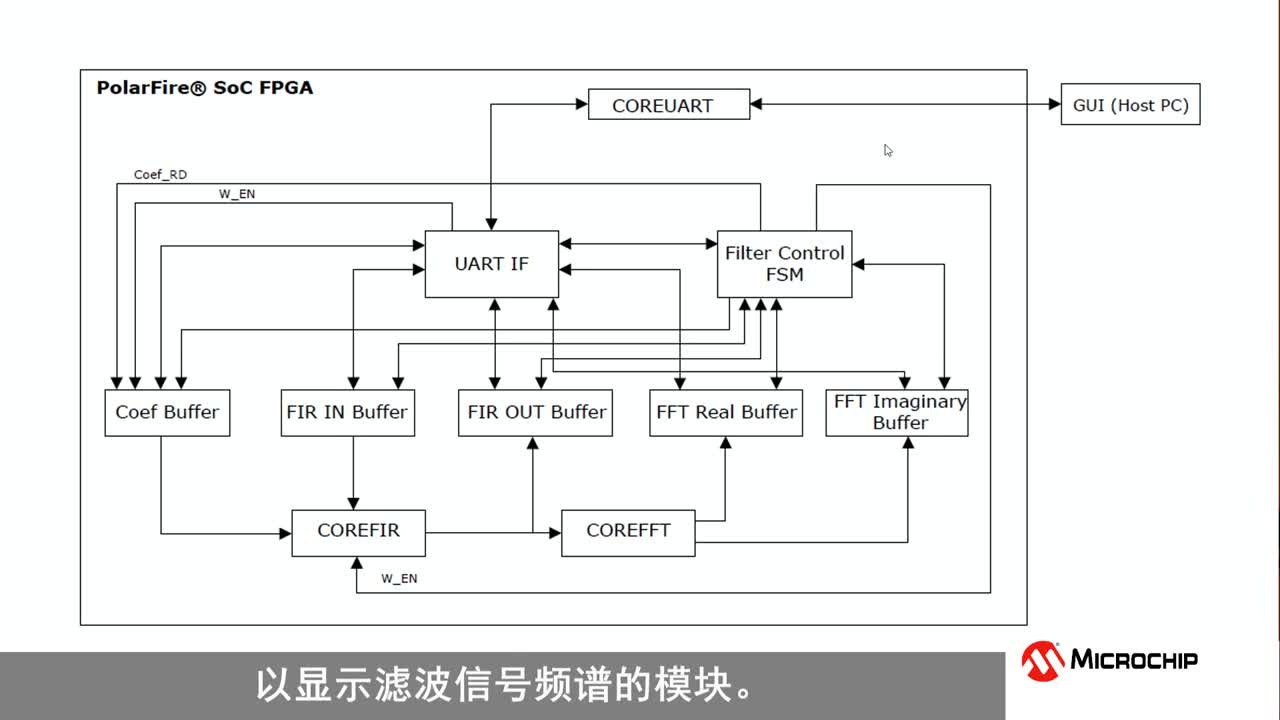
��Դ��AVNET �F(xi��n)���ɾ����T��� (FPGA) ���˹����� (AI) ��(y��ng)�Î������S����(y��u)�ݡ��D��̎���Ԫ (GPU) �͂��y(t��ng)������̎���Ԫ (CPU) ��ȣ��냞(y��u)���ӣ� ���^�˹����� (AI)����ָ�܉����������ķ�ʽ�����Q�ߵķ���C(j��)�����ܣ����w���Дࡢ˼�����m��(y��ng)����D������ �о���˾ Statista �A(y��)�y���� 2025 �꣬�˹����ܵ�ȫ���Ј�Ҏ(gu��)ģ���_(d��) 1260 �|��Ԫ���� 2030 �꣬�˹��������Ї��������Ͱ�(li��n)�� GDP �е�ռ�Ȍ��քe�_(d��)�� 26.1%��14.5% �� 13.6%�� �˹������Ј����w�˸��(y��ng)�ã�������Ȼ�Z��̎�� (NLP)���C(j��)�����^���Ԅ�(d��ng)�����C(j��)���W(xu��)��(x��)���C(j��)��ҕ�X���ںܶഹֱ�ИI(y��)���˹����ܵIJ�����Ѹ�����������ڄ�(chu��ng)����һ�(xi��ng)����ļ��g(sh��)׃������c��(g��)����X�������֙C(j��)�ij��F(xi��n)���ᲢՓ�� �M���˹�������Ҫ��ه��ģ�M���˼�S�ľ����㷨����Ӳ��ͬ�Ӱl(f��)�]����Ҫ���á��˹����ܲ�������������ҪӲ����Q�������F(xi��n)���ɾ����T��� (FPGA)���D��̎���Ԫ (GPU) ������̎���� (CPU)�� �˹����� (AI) �����g(sh��)�Z�����Դ���о��ˆT Allen Newell��Cliff Shaw �� Herbert Simon �� 1956 �ꄓ(chu��ng)���� Logic Theorist ����Logic Theorist �������m�� (RAND) ��˾�Y���_�l(f��)��ּ��ģ�M���Q���}�ļ��ܡ�Logic Theorist ��ҕ���һ���˹����ܳ����� 1956 �����º���ʲ�����_(d��)��é˹�W(xu��)Ժ���_(d��)��é˹�˹������ļ��о��(xi��ng)Ŀ (DSRPAI) ���M(j��n)���˽�B�� ÿ�N���������Ѓ�(y��u)ȱ�c(di��n)�������҂����M(j��n)һ��̽ӑ�� FPGA �F(xi��n)���ɾ����T��� (FPGA) �Ǿ��пɾ���Ӳ���Y(ji��)��(g��u)�������·�����c�D��̎���Ԫ (GPU) ������̎���Ԫ (CPU) �IJ�֮ͬ��̎���ڣ�F(xi��n)PGA ̎������(n��i)���Ĺ����·δ��(j��ng)�^Ӳ�g�̡���ˣ�F(xi��n)PGA ̎�������Ը���(j��)��Ҫ�M(j��n)�о��̺��¡����⣬�O(sh��)Ӌ(j��)�ˆTҲ���^�_ʼ��(g��u)����(j��ng)�W(w��ng)�j(lu��)������ȫ����(j��)����������� FPGA�� FPGA ���ÿ��ؾ��̡��������õļܘ�(g��u)���������®����˹������I(l��ng)��(y��u)�����@��ʹ�O(sh��)Ӌ(j��)�ˆT���Կ��ٜyԇ���㷨�����ڟo���_�l(f��)�Ͱl(f��)����Ӳ��������ڿs�̮a(ch��n)Ʒ���Еr(sh��)�g��(ji��)ʡ�ɱ����渂����(y��u)�����@�� FPGA ����ٶȡ��ɾ����Ժ��`���ԣ������ˌ��ü����· (ASIC) �_�l(f��)�����еijɱ��͏�(f��)�s�ԣ�ʹ��Ч�ʴ����ߡ� FPGA ����Ҫ��(y��u)�ݰ����� • ���t���ͣ�����Խ�� FPGA ���Ԏ������ӕr(sh��)��ͬ�r(sh��)Ҳ�ǿɴ_���Ե��ӕr(sh��)(Deterministic Latency)��DL ����ģ�͌��ij�ʼ��B(t��i)��o������ʼ�l���B�m(x��)�a(ch��n)����ͬ��ݔ����DL �ṩ��֪��푑�(y��ng)�r(sh��)�g�����ںܶ���Ї�(y��n)��Ӳ�r(sh��)��Ҫ��đ�(y��ng)�ó�����ԣ��@һ�c(di��n)���P(gu��n)��Ҫ���ɴˣ����Լӿ��Z���R(sh��)�e��ҕ�l�����\(y��n)��(d��ng)�R(sh��)�e�Ȍ�(sh��)�r(sh��)��(y��ng)�ó���Ĉ�(zh��)���ٶȡ� • �ɱ�Ч�棺������ɺ�F(xi��n)PGA ����ᘌ���ͬ�Ĕ�(sh��)��(j��)��ͺ������¾��̣�������?y��n)�?y��ng)�ø�׃����Ҫ��Ӳ�����£��Ķ��w�F(xi��n)���O�ߵăr(ji��)ֵ���O(sh��)Ӌ(j��)�ˆT���Ԍ��������ܣ�����D��̎�����̣����ɵ�ͬһоƬ�ϣ����� FPGA ��(sh��)�F(xi��n)�˹���������Ĺ��ܣ��Ķ����ͳɱ�����(ji��)ʡ�·����g��FPGA �Įa(ch��n)Ʒ���������^�L�����@��������(y��ng)�õČ�(sh��)���ԣ����L����Ч�r(sh��)�g���_(d��)��(sh��)��������(sh��)ʮ�ꡣ�ɴˣ���ɞ��˹��I(y��)�����պ��졢�������t(y��)�����\(y��n)ݔ�I(l��ng)�������֮�x�� • ��ԴЧ�ʣ� ���� FPGA���O(sh��)Ӌ(j��)�ˆT�܉�?q��)�Ӳ���M(j��n)���{(di��o)����ƥ�䑪(y��ng)���������� INT8 �������_�l(f��)�����ǃ�(y��u)���C(j��)���W(xu��)��(x��)��ܣ��� TensorFlow �� PyTorch������Ч������ͬ�r(sh��)��INT8 ����Ҳ�� NVIDIA® TensorRT �� Xilinx® DNNDK ��Ӳ��������ṩ�����˝M��ĽY(ji��)������?y��n)?INT8 ʹ�� 8 λ����(sh��)�����Ǹ��c(di��n)��(sh��)��ͬ�r(sh��)ʹ������(sh��)�\(y��n)������Ǹ��c(di��n)�\(y��n)�㡣�m��(d��ng)ʹ�� INT8 ���Ԝp�ك�(n��i)���Ӌ(j��)�����������ʹ��(n��i)��͎���ʹ�����p�� 75������Ҫ����̵đ�(y��ng)���У��@һ�c(di��n)���ڝM�㹦��Ҫ��������P(gu��n)��Ҫ�� FPGA ���Բ���̎����N���ܣ������ܞ��ض����ܷ����������ض��YԴ���������˲�������ԴЧ�ʡ�FPGA �ܘ�(g��u)��(d��)�أ��������ֲ�ʽ��(n��i)�����Y(ji��)��(g��u)�У�ʹ������������̎���Ԫ���c GPU �O(sh��)Ӌ(j��)��ȣ��@�N�O(sh��)Ӌ(j��)���������t������Ҫ���ǜp���˹��ġ� GPU �D��̎���Ԫ (GPU) ����_�l(f��)��������Ӌ(j��)��C(j��)�D�Ρ�̓�M�F(xi��n)��(sh��)Ӗ(x��n)���h(hu��n)����ҕ�l���������Ӌ(j��)����c(di��n)�����L�ƎΌ���������ɫ��˹�������Ҫ�@�óɹ�������Ҫ�������ڷ����͌W(xu��)��(x��)�Ĕ�(sh��)��(j��)���@����Ҫ��(qi��ng)���Ӌ(j��)���������(zh��)���˹������㷨���D(zhu��n)�ƴ�����(sh��)��(j��)��GPU ֮�����܉��(zh��)�д����������?y��n)��䌣�T�O(sh��)Ӌ(j��)���ڿ���̎����Ⱦҕ�l�͈D�Εr(sh��)ʹ�õĴ�����(sh��)��(j��)������Ӌ(j��)������������GPU �ڙC(j��)���W(xu��)��(x��)���˹����ܑ�(y��ng)���I(l��ng)���H�ܚgӭ�� GPU �dz��m�ϲ���̎����������Ӌ(j��)��������g(sh��)�\(y��n)�㡣�ɴˣ��ھ����؏�(f��)����ؓ(f��)�d�ҿ����B�m(x��)���؏�(f��)��(zh��)�еđ�(y��ng)�ó����У������@�����̎���ٶȡ�GPU �Ķ��r(ji��)���Բ��ø����Խ�Q��������ͨ�@�����������ڞ����ꡣ ��һ���棬�� GPU �ό�(sh��)ʩ�˹����ܵľ�����Ҳ�_��(sh��)���ڡ�GPU �ṩ������ͨ������ ASIC �O(sh��)Ӌ(j��)�����߾��Ќ��T�O(sh��)Ӌ(j��)�����˹����ܑ�(y��ng)�õ�оƬ��GPU �߂䏊(qi��ng)���Ӌ(j��)�����������s��������Ч���a(ch��n)���ğ���Ҳ�^�ߡ�������(hu��)Ӱ푑�(y��ng)�õ������ԣ��p�����ܲ����Ʋ����h(hu��n)������͡��ڸ����˹������㷨�������¹��ܷ��棬������Ҳ�o���c FPGA ̎�������ᲢՓ�� CPU ����̎���� (CPU) ���S���O(sh��)����ʹ�õĘ�(bi��o)��(zh��n)̎�������c FPGA �� GPU ��ȣ�CPU �ܘ�(g��u)�ă�(n��i)�˔�(sh��)�����ޣ�ᘌ������̎���M(j��n)���˃�(y��u)����Arm® ̎���������ǂ�(g��)���⣬���䷀(w��n)���،�(sh��)ʩ�ˆ�ָ�����(sh��)��(j��) (SIMD) �ܘ�(g��u)������ͬ�r(sh��)��������(g��)��(sh��)��(j��)���M����ˣ����������ԟo���c GPU �� FPGA ������ ���ڃ�(n��i)�˔�(sh��)�����ޣ�CPU ̎�����o����Ч�ز���̎�����_�\(y��n)���˹������㷨����Ĵ�����(sh��)��(j��)��FPGA �� GPU �ļܘ�(g��u)�O(sh��)Ӌ(j��)�����ܼ�����̎�����ܣ����Կ��ٲ���̎������(g��)�΄�(w��)��FPGA �� GPU ̎������(zh��)���˹������㷨���ٶȱ� CPU ���졣�@��ζ���c CPU ��ȣ��˹����ܑ�(y��ng)�ó������(j��ng)�W(w��ng)�j(lu��)�� FPGA �� GPU �ϵČW(xu��)��(x��)�ͷ���(y��ng)�ٶ�Ҫ��Îױ��� CPU �_��(sh��)����һЩ��ʼ�r(ji��)��(y��u)�ݡ�ʹ�����Ĕ�(sh��)��(j��)��Ӗ(x��n)��С����(j��ng)�W(w��ng)�j(lu��)�r(sh��)������ʹ�� CPU������Ҫ���^�L�r(sh��)�g�Ĵ��r(ji��)���c���� FPGA �� GPU ��ϵ�y(t��ng)��ȣ����� CPU ��ϵ�y(t��ng)�\(y��n)���ٶ�Ҫ���öࡣ���� CPU �đ�(y��ng)�ó���߀������һ��(g��)��(y��u)�ݣ��Ǿ��ǹ��ġ��c GPU ������ȣ�CPU ��Ч���ߡ� �͙C(j��)���W(xu��)��(x��) (TinyML) TinyML ��ҕ���˹����ܰl(f��)չ����һ��(g��)�l(f��)չ�A�Σ����L���^��(qi��ng)�š��M�� FPGA��GPU �� CPU ̎�������\(y��n)�е��˹����ܑ�(y��ng)�ó����ܘO�䏊(qi��ng)���o�����֙C(j��)���o�˙C(j��)�Ϳɴ�����(y��ng)�ó�����龳��ʹ�á� �B���O(sh��)����څ�ռ�����Ҫ�M(j��n)�б���?c��i)?sh��)��(j��)���������͌��Ƶ���ه����(sh��)�F(xi��n)�������ܡ�TinyML ���������������\(y��n)�е�߅���O(sh��)���(n��i)��(sh��)�F(xi��n)�����t�����ĺ͵͎���������ģ�͡� ��ͨ���M(f��i)�� CPU �Ĺ����� 65 �� 85 ��֮�g���� GPU ��ƽ�������� 200 �� 500 ��֮�g�����֮�£����͵����������ĵĹ��ʞ�����ߔ�(sh��)���������ăH��ǧ��֮һ����ˣ�TinyML �O(sh��)���܉�����늳ع���\(y��n)�Д�(sh��)�ܡ���(sh��)��������(sh��)�꣬ͬ�r(sh��)��߅���\(y��n)�ЙC(j��)���W(xu��)��(x��)��(y��ng)�ó��� TinyML ֧�� TensorFlow Lite��uTensor �� Arm �� CMSIS-NN �ȿ�ܣ����˹������cС�ͻ�(li��n)�O(sh��)����Y(ji��)�ϡ� TinyML �ă�(y��u)�ݰ����� �� ��ԴЧ�ʣ� ���������ĘO�ͣ����h(yu��n)�̰��b���Ƅ�(d��ng)�O(sh��)��������x�� �� �����t�� ������߅������̎�픵(sh��)��(j��)���o�茢��(sh��)��(j��)��ݔ?sh��)��ƶ��M(j��n)���������ɴ˴�����O(sh��)�����t�� �� �[˽�� ��(sh��)��(j��)���Դ惦(ch��)�ڱ��أ��o��惦(ch��)���Ʒ���(w��)���ϡ� �� �����p�٣� �����ˌ��ƶ���������ه�ԣ�����ȵp���ˎ������}�� ���ڲ��m��ʹ�� FPGA��GPU �� CPU ��С��߅���O(sh��)���Ҏ(gu��)ģ���đ�(y��ng)�ã�ʹ�� MCU �� TinyML δ��ʹ��ǰ���V韡� Ҫ�c(di��n) �˹�������Ҫ��������Ӳ����Q������FPGA��GPU �� CPU�������ٶȺͷ���(y��ng)�r(sh��)�g���P(gu��n)��Ҫ���˹����ܑ�(y��ng)�ö��ԣ�F(xi��n)PGA �� GPU �ڌW(xu��)��(x��)�ͷ���(y��ng)�r(sh��)�g������ڃ�(y��u)�ݡ��M�� GPU �܉�̎���˹����ܺ���(j��ng)�W(w��ng)�j(lu��)����Ĵ�����(sh��)��(j��)����ȱ�c(di��n)Ҳ���^���@��������Ч��ɢ�ᣨ���������������Լ���(y��ng)�ó����¹��ܺ��˹������㷨���µ�������FPGA ���˹����ܑ�(y��ng)�ú���(j��ng)�W(w��ng)�j(lu��)�Г����P(gu��n)�I��(y��u)�ݣ�������ԴЧ�ʡ���(sh��)���ԡ��������Լ������˹������㷨�ĺ����ԡ� ���⣬F(xi��n)PGA �_�l(f��)ܛ��Ҳȡ�����ش��M(j��n)չ���@�������˾��̺;��g�y�ȡ�Ӳ���x�����˹����ܑ�(y��ng)�ó���ijɔ��P(gu��n)�I���ڡ���K�Q��֮ǰ��Ո�м�(x��)�о���֔(j��n)����� ����Ҫ����һ�΄�(chu��ng)���x����m�ļ��g(sh��)������飬�Ա����Ч�ʣ����͝����L(f��ng)�U(xi��n)�����̶ȵ����ӯ�����������ˎ�����(sh��)�F(xi��n)Ŀ��(bi��o)�����������Ԟ�����������c�˹������I(l��ng)��ֵ����ه��ȫ���g(sh��)������齨���B�ӡ��ɴˣ������Ԍ����F���YԴ������֪�R(sh��)�a(ch��n)��(qu��n)��(chu��ng)�¼�����������(y��u)�����@���I(l��ng)���҂����c���o�ܺ�����ȫ���ṩ����֧�֣��������Įa(ch��n)Ʒ���Ј���Ó�f�������s�̮a(ch��n)Ʒ���Еr(sh��)�g���Aȡ�������⡣ |