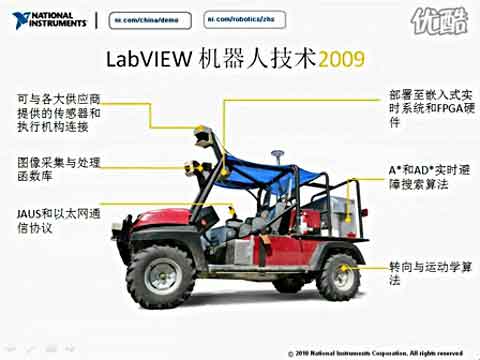
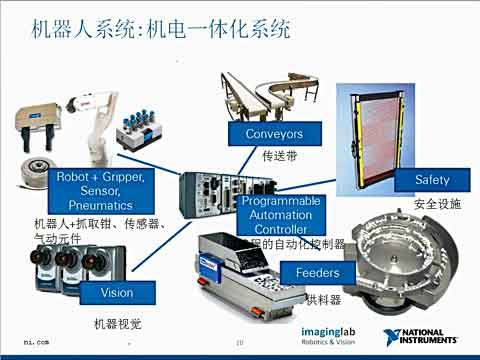
|
來(lái)源:大半導(dǎo)體產(chǎn)業(yè)網(wǎng) 據(jù)報(bào)道,近日,谷歌和柏林工業(yè)大學(xué)的團(tuán)隊(duì)重磅推出了史上最大的視覺(jué)語(yǔ)言模型——PaLM-E。通過(guò)PaLM-540B語(yǔ)言模型與ViT-22B視覺(jué)Transformer模型相結(jié)合,PaLM-E參數(shù)量高達(dá)5620億(GPT-3的參數(shù)量為1750億)。 作為一種多模態(tài)具身視覺(jué)語(yǔ)言模型(VLM),PaLM-E不僅可以理解圖像,還能理解、生成語(yǔ)言,可以執(zhí)行各種復(fù)雜的機(jī)器人指令而無(wú)需重新訓(xùn)練。谷歌研究人員還觀察到一些有趣的效果,這些效果顯然來(lái)自PaLM-E的核心——大型語(yǔ)言模型。PaLM-E表現(xiàn)出了“正遷移”能力,即它可以將從一項(xiàng)任務(wù)中學(xué)到的知識(shí)和技能遷移到另一項(xiàng)任務(wù)中,從而與單任務(wù)機(jī)器人模型相比具有“顯著更高的性能”。 谷歌研究人員計(jì)劃探索PaLM-E在現(xiàn)實(shí)世界場(chǎng)景中的更多應(yīng)用,例如家庭自動(dòng)化或工業(yè)機(jī)器人。他們希望PaLM-E能夠激發(fā)更多關(guān)于多模態(tài)推理和具身AI的研究。 |